串口环形缓冲区FIFO的设计模式
[!warning] Important
This post is currently in progress.
1. 理论
对于一个线性缓冲区 Buffer,假设往其中不断地填入数据包,那么很快就会发生数据溢出。

然而,如果在存入的同时对前面的一帧数据进行处理后释放其占用的空间,这样缓冲区就出现了富余,此时就可以将原本塞不下的数据存到前面,比如说这里数据包 A 已经完成解析,就可以将其推出缓冲区,而数据包 C 的溢出部分就可以存入前面这一块空出来的位置。

这实际上就形成了一种遵循 FIFO ( First In First Out ) 的环形数据结构:
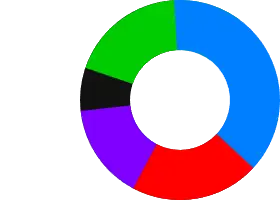
在上面的例子中也就是:
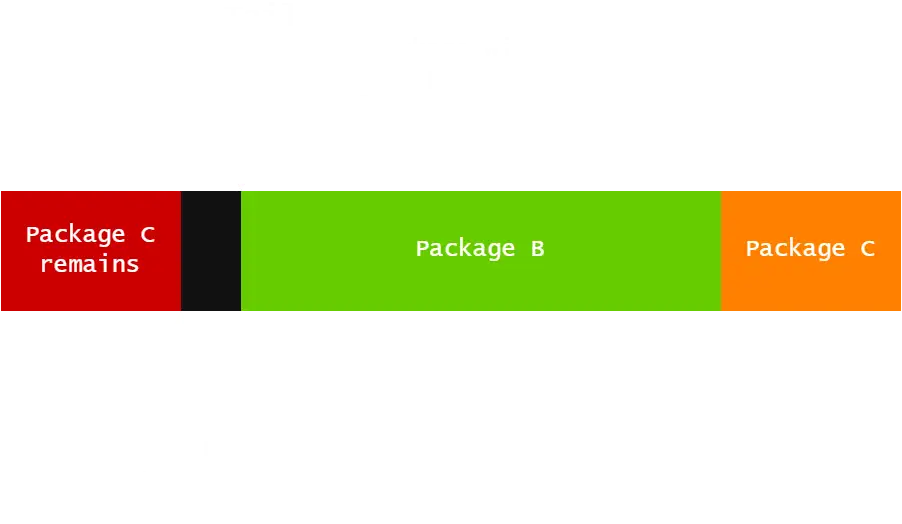
其中:
Head为数据包往缓冲区中开始写入的位置Tail为数据包从缓冲区中开始读出的位置
由图可以看出 Head 并不总是领先于 Tail ,比如说写入的数据包溢出,一处部分就将回到开头。上图中新数据会从 Package C remains 末尾开始写入,而从 Tail 开始 Package B 将会被弹出。
随着数据的不断写入,Head Index 增加,一旦 Head index > 缓冲区总长,那么 Head Index 就会回到开头。同样,随着数据的不断弹出,Tail_Index 增加,一旦大于缓冲区总长,那么也会回到开头。
所以在这个数据结构中,Head 和 Tail 实际上有这样几种情况:
Head>TailHead<TailHead=Tail
然而第三种情况下数据读写的位置重合,很难进行操作,所以一般约定头尾之间留一位不写满:
比如说认为这样就处于满的状态。
2. 算法实现
2.1 变量
1 | static constexpr uint16_t MAX_FIFO_SIZE{256}; |
声明环形缓冲区以及两个索引变量,分别指示数据的头尾。
2.2 方法
首先我们认为,head_index 与 tail_index 与 Ring 的下标是一一对应的,也就是在 MAX_FIFO_SIZE = 256 的情况下,head_index & tail_index 都在 [0,255] 这个范围内。
2.2.1 Get_xxxSpace
这一组方法用于获取数组中各部分的容量。
1 | uint16_t Get_OccupiedSpace() |
获取缓冲区中被占用(数据)量。
假设一个 9 字节的缓冲区,存有 5 字节的数据,可能的形式为:
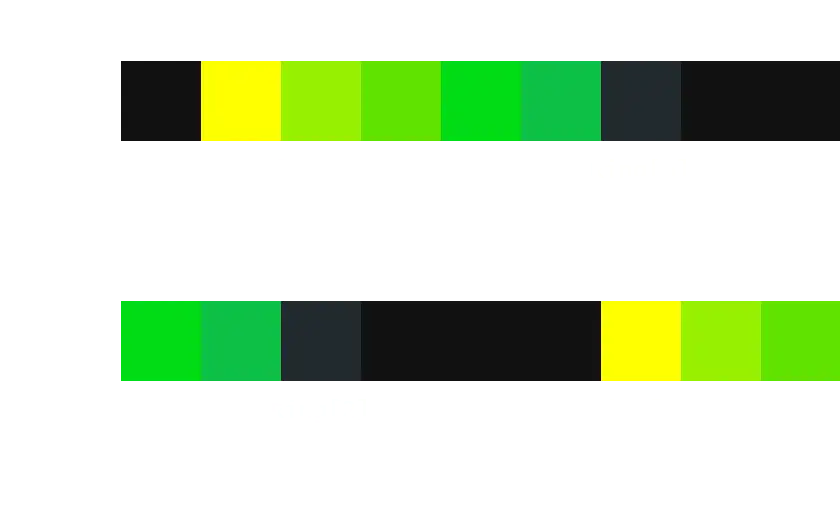
1 | (6-1+9)%9 = 5 |
从绝对意义上来说:$$head-tail = length$$,而当 head 回到开头的时候,由于限制 head 必然会回到开始索引,导致该式为一个负数。但是从环形模型上看,head 此时的距离已经经过一次缓冲区的总长,所以将一个缓冲区总长补偿上去,也就是将环延展成一条铺开的无限线性直线。这个时候:
$$head+length_{R}$$
的意义相当于 head 的绝对索引(实际上缓冲区在 Ring[8] 就已经结束):

很显然此时$$head+length_R-tail = length$$
那么对于
$$\begin{cases}length&=head-tail&,head>tail\length&=head+length_R-tail&,haed<tail\end{cases}$$
根据模 $N$ 运算的定理:
$$(a−b)modN=(a+N−b)modN$$
方程组可以简化为:
$$(head+length_R-tail)\space mod\space (length_R)$$
也就是函数内的算法。
为了对运行速度做优化,在这里总是将缓冲区数组的长度设置为 $2^k$,这样的结果是
1 | head_index + MAX_FIFO_SIZE - tail_index) % MAX_FIFO_SIZE |
实际等价于
1 | head_index + MAX_FIFO_SIZE - tail_index) & (MAX_FIFO_SIZE-1) |
而后者的执行速度更快。
1 | uint16_t Get_FreeSpace() |
前面说过,由于索引与结构的限制,该缓冲区不能被填满,这就导致总有一位是空的,也就是:
$$length_R = length_{O}+length_{F}+1$$
所以获取空闲空间长度的时候就需要额外减去一个 1。
2.2.2 Push & Pop
Push & Pop 也就是需要存入的数据调用 Push 送入缓冲区,而已经分析完毕的数据调用 Pop 弹出缓冲区。
1 | void Push(uint8_t *data, uint16_t length) |
如果数据包本身根本就无法存入缓冲区,比如说其总长度比缓冲区一共的可用长度还要长,那么判断数据无法存入。
总是考虑将数据包拆分成两段进行送入:
first_chunk- 能线性存入缓冲区直至末尾的部分second_chunk- 需要回到缓冲区开头存入的另一部分
其中:
1 | first_chunk = std::min<uint16_t>(length,MAX_FIFO_SIZE - head_index), |
表示,如果数据的长度 length 超越缓冲区剩余长度,那么第一份数据只能够利用从 head_index 开始的剩余部分长度(此时该值 MAX_FIFO_SIZE-head_index 小于 length),而如果没有,那么可利用区域的长度就是数据的总长 length 。
1 | second_chunk = length - first_chunk; |
当数据长度大于剩余长度时,该值不为 0 ,表示需要在开头存入第二部分数据。当数据长度小于剩余长度时,该值为 0,表示没有第二部分数据需要存入。
1 | std::memcpy(&Ring[head_index],data,first_chunk); |
分别在对应位置存入数据。
1 | head_index = (head_index + length -1) & MAX_FIFO_SIZE; |
最后更新 head 的位置。
接下来看如何将数据弹出.
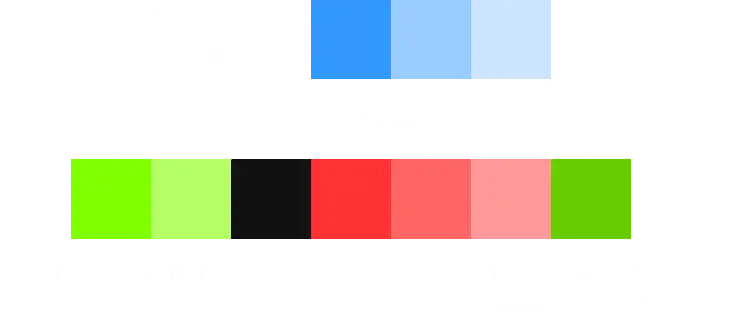
考虑一个极限情况,假如现在 tail 在数据包 A 的第一个字节上,而 head 在数据包 B 之后,也就是空余的那一位上,这种情况下缓冲区已满,想要存下 3 字节的数据包 C,就必须请准备送去解析的数据包 A 弹出以进行空间周转。
1 | void Pop(uint8_t *data, uint16_t length) |
这也就是一个 Push 的镜像版本,从 tail_index 位置开始弹出 length 长度的数据到 data中,只不过操作对象与数据搬运顺序稍有不同。
2.2.3 Todo
1 | TODO - 2026/2/19 |
