排序算法 I : 插入/快速/归并/堆
A. 直接插入排序
1 |
|
默认数组的第一个元素 arr[0] 已经进行了排序,从 arr[1] 开始遍历数组,第 i 个元素 arr[i] 存储为 key;从这个元素的前一个元素 arr[j] 开始向数组首部前进(这个时候 j 就成为向前遍历的索引),如果观测到前面的元素大于 key,那么就需要将其向前进一位 (覆盖 arr[i]也无妨,因为值已存储),直到某个元素不再大于 key,那么将 key在此处的下一位插入。
B. 快速排序
此处使用 Hoare 的双指针法:
1 |
|
首先,函数 Partition 入口参数为一个数组以及它两端的数组下标 start 和 end
, 取 i 和 j 分别向两端拓展一位(因为下面的 do while 会先执行一次,这之后 i 与 j 始终位于 start 与 end 之间)。
pivot 是选取用来作为比较对象的数组元素,此处取第一位。这个函数的目的就是以 pivot 为中心,将比它大的元素放在数组右边,小的放在数组左边。
这之后,先从左侧开始向中间遍历,如果 arr[i](即左侧部分)始终满足小于 pivot ,那么就继续向右遍历,直到找到一个 arr[i] 大于 pivot ,这之后右侧的指针也开始遍历,直到也找到一个 arr[j] 小于 pivot. 这时候这两个元素的位置应当互换以满足大小顺序。
需要注意的是 pivot 作为左侧的第一个元素,也会立即参与交换。
循环往复,直到 i 遍历到 j的位置,满足 arr[i]>pivot ,此时 i=j 。j 继续往右遍历,必然去到 i-1 的位置,且 arr[j]=arr[i-1]<pivot ,j<i。由于满足 i>=j ,此时
1 | if (i >= j) return j; |
退出循环并记录 j(新分界点)的位置。
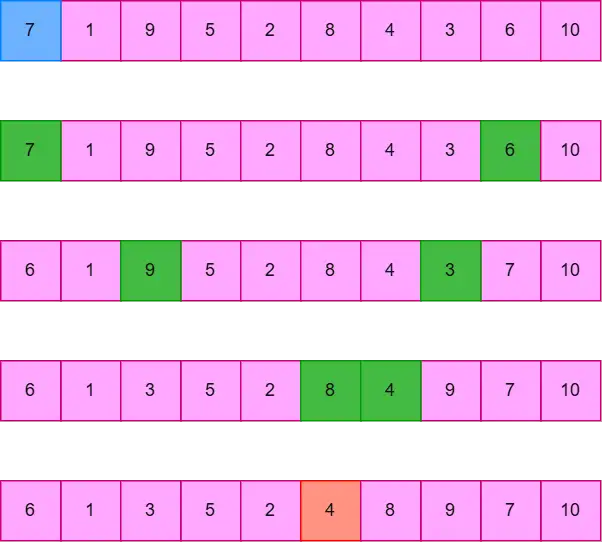
比如说上面这个过程就是以 arr[0]=7 为 pivot 最终得到新分界点 j=arr[5]=4。
这之后,数组满足 [0,j]中的元素都小于 pivot [j+1,end] 中的元素都大于等于 pivot 。那么对于 [0,j] 和 j+1,end 这两个区间递归进行操作,也就是各个区间的第一个元素作为新的 pivot.
1 | void Quick_Sort(int *arr, int start, int end) |
总函数就是这样的一个过程,首先进行第一次拆分,从分界点 j 也即 divide 划分 [start,divide] 和 [divide+1,end] 两个区间,并且对各自的区间递归调用一次 Quick_Sort() , 直到区间不可再分 (start>=end) ,这时保证最小的元素都已经在最小的区间内完成排序。
C. 归并排序
1 |
|
merge() 函数的功能是将两个 有序 的数组进行排序。
先假定一个 arr 数组,从 mid 作为分界点,[start,mid] 和 (mid,end] 是两块 各自有序 的数组,比如说 [1,2,5,7,8,9,3,4,6,10] 可以分为 [1,2,5,7,8,9] 和 [3,4,6,10]。
申请两块内存来存储这两个有序数组
1 | int n1 = mid - start + 1, |
这之后,同时遍历左右两个数组,比较每一个 left[i] 与 right[j], 将较小者按顺序写回 arr。由于这两个数组各自是有序的,按这个方法就能将这两个数组中的元素有序合并。
1 | while(i < n1 && j < n2) |
当然由于 i 与 j 不一定相等,所以当一边的数组已经耗尽,那么就需要将另一边剩余的元素全部排进 arr , 也就是两个 while 循环。由于耗尽(或已排入 arr)的元素必定有序且小于剩余元素,且剩余元素本身是有序的,所以可以直接这样塞进去。最后得到了一个有序的 arr.
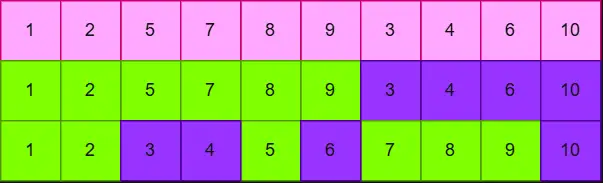
要如何去保证 arr 一定是由两个有序的数组组成的呢?首先对于一个数组来说,单元素数组必定是有序的,所以任意一个 2 元素的数组必定会满足 merge 的条件。
假如一个有一个乱序数组,需要做的就是把它分成 N 个单元素数组,由于现在每两个数组都满足有序条件,就可以进行有序合并 merge 了(N 为奇数的时候,单独剩下的和第一次合并好的有序 2 元素数组合并即可)。
1 | void Merge_Sort(vector<int>& arr, int start, int end) |
递归条件为 start<end ,也就是当数组为单元素数组时,递归停止。
递归的两个 Merge_Sort 将整个乱序数组不断拆分为左右两部分(这是因为每一级递归,都会对当前级的数组以 mid 为界再拆分),比如说:
[7,1] 左拆分之后就是 [7] ,由于不满足 start < end 条件,返回到 [7,1] 的右拆分,得到 [1] ,同理不满足,返回到 [7,1] 的 merge 将 [1] [7] 有序合并成为 [1,7],又因为上述操作属 [7,1,5,3] 的 merge_sort(arr,start,mid) 流程,所以右侧的 [5,3] 也进行一次,最后 [7,1,5,3] 的 merge 将 [1,7] [3,5] 合并为 [1,3,5,7] ,并且返回更上一级…

如此循环往复,直到恰好最后两块有序数组最后一次 merge 合并成完整的 N 元素有序数组。
D. 堆排序
堆是一根完全二叉树,也就是叶节点连续从左排列。
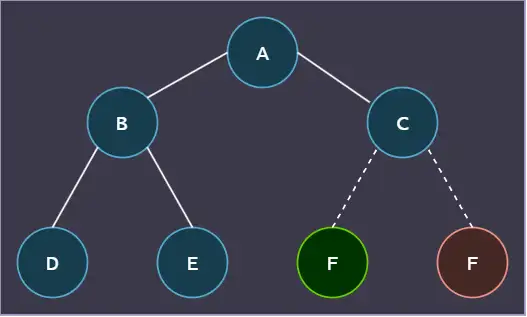
比如这里 F 就不可以放在 C 的右节点。
当所有父节点大于等于子节点时,堆成为大根堆,反之成为小根堆,这表示根节点最大或者最小,用数组存储上面的堆结构就是 [A,B,C,D,E,F] ,满足逐层,且每层自左往右顺序排列。
此时对于节点 i ,其具有序号为 (i-1)/2 的父节点以及 2i+1 2i+2 的左 / 右子节点。
对于一个非堆的数组,考虑遍历其所有的节点,如果某个节点不满足堆的结构,那么就对其进行修正。比如说大根堆的 下滤:当一个父节点小于其子节点时,那么互相交换,将小的节点下滤到合适的位置。
1 | void Heapify(vector<int>& arr, int n, int i) |
遍历到的节点为 arr[i] ,其具有子节点 arr[left] 与 arr[right],比较左右节点,更新 largest ,如果父节点 i 不满足 largest ,那么进行下滤(交换)。同时,该父节点为了保证能够去到合适位置,需要不断向下进行此操作,所以假设以及建立的堆有 n 层,该父节点就必须在 n 层内递归下滤,直到 largest = i 表示其确实去到了某层的最大位置,这个节点的处理完成。
1 | void Heap_Sort(vector<int>& arr) |
首先需要对数组建堆。由于叶节点肯定是堆,于是就从最后一个非叶子节点(序号为 n/2-1, 因为 n 必定是叶节点)开始进行下滤,并最终建立起一个大根堆。
此时,堆处于局部有序状态,因为不能保证同一层的各个节点是有序的,只能保证父子节点之间的有序(而且在数组中整体呈现逆序)。
所以,这时做的操作是,将最大的元素(由于建堆,所以可以保证父节点一定最大)与最后一个叶节点交换,然后对交换后除最大元素外的 n 个元素再进行一次建堆:

然后 [1,5,3,4] 建堆就会变成 [5,4,3,1],合并 [5,4,3,1,10],这之后将 5 与 1 交换,重复此过程,直到得到 [1,3,4,5,10] 为止。
本质就是构造一个满足堆序性质的完全二叉树以得到一定最大的堆顶元素并移出,再重新调整剩余结构找到下一个,重复。
